
 DataGrip使用Hive On Spark提示创建Session失败原创
DataGrip使用Hive On Spark提示创建Session失败原创
# DataGrip使用Hive On Spark提示创建Session失败
# 1 现象
Hive配置Hive On Spark,连接集群使用原生Hive客户端执行Sql能正常使用Spark引擎:
Query Hive on Spark job[2] stages: [2, 3]
Spark job[2] status = RUNNING
--------------------------------------------------------------------------------------
STAGES ATTEMPT STATUS TOTAL COMPLETED RUNNING PENDING FAILED
--------------------------------------------------------------------------------------
Stage-2 ........ 0 FINISHED 1 1 0 0 0
Stage-3 ........ 0 FINISHED 2 2 0 0 0
--------------------------------------------------------------------------------------
STAGES: 02/02 [==========================>>] 100% ELAPSED TIME: 15.22 s
--------------------------------------------------------------------------------------
Spark job[2] finished successfully in 15.22 second(s)
OK
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
使用DataGrip连接Hive,执行语句报错:
[42000][40000] Error while compiling statement: FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session 2cfcb3f3-b9c7-4d43-bb54-d729a908b6e8
1
# 2 解决办法
参考网上说调大hive-env.sh中HADOOP_HEAPSIZE,错误仍存在
export HADOOP_HEAPSIZE=4096
1
使用beeline连接hive,发现也报同样错误,定位为hiveserver2版本问题:
Error: Error while compiling statement: FAILED: SemanticException Failed to get a spark session: org.apache.hadoop.hive.ql.metadata.HiveException: Failed to create Spark client for Spark session f8aafe0d-b6ff-4e9a-aa1e-4caaedc8a161 (state=42000,code=40000)
1
查看DataGrip连接Hive的配置,默认也是连接hiveserver2的:
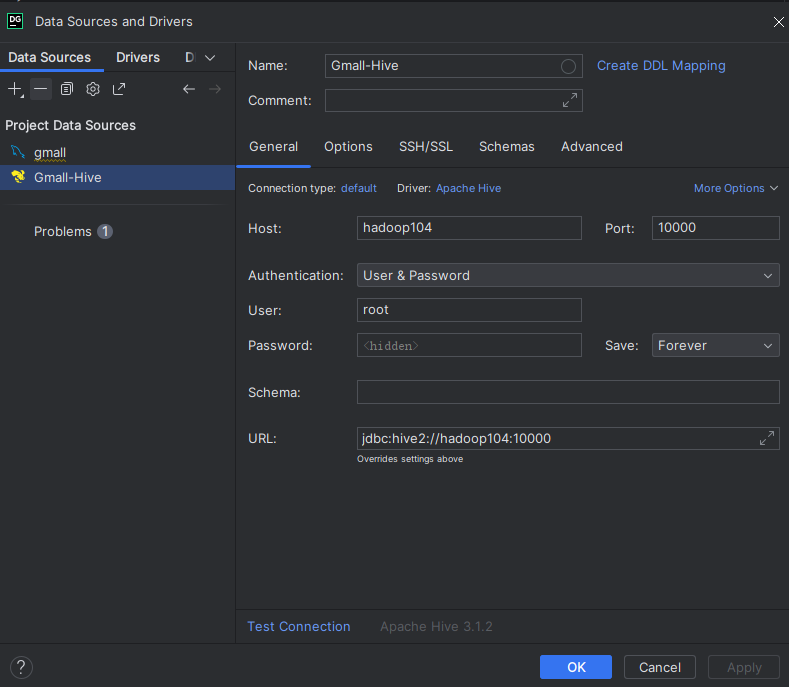
修改连接使用ssh隧道:
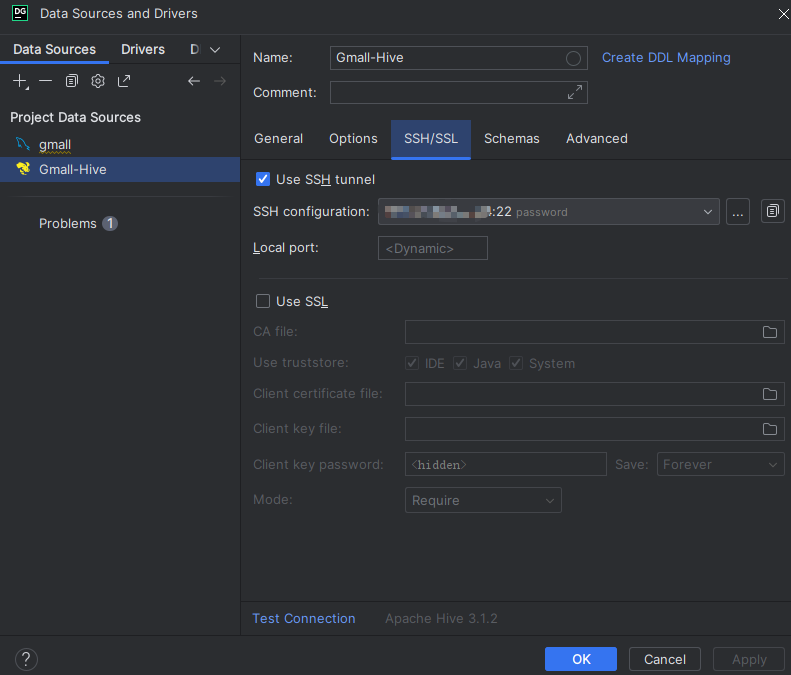
重新运行通过,使用spark引擎执行速度快很多:
default> SELECT t2.user_id,t2.login_date,date_add(t2.login_date,t2.rn) as date2,t2.rn
FROM
(
SELECT t1.user_id, t1.login_date
,row_number() over (partition by user_id order by t1.login_date ) as rn
FROM
(
SELECT user_id,login_date
FROM dayly_sql.user_login_log
WHERE login_date BETWEEN date_sub('2024-04-07',7) AND '2024-04-07'
GROUP BY user_id,login_date
)t1
)t2
[2024-07-14 20:23:59] 11 rows retrieved starting from 1 in 1 m 14 s 141 ms (execution: 1 m 13 s 911 ms, fetching: 230 ms)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
2
3
4
5
6
7
8
9
10
11
12
13
14

上次更新: 2025/06/22, 18:51:19
